머신러닝 학습알고리즘에 대해 학습해보고자 한다. SVM,KNN,의사결정나무,랜덤포레스트,앙상블,로지스틱 회귀,선형회귀 등 7가지 알고리즘에 대해 확인해보고자 한다.
*SVM(Support Vector Machine)
주어진 데이터들을 가능한 멀리 두개의 집단으로 분리시키는 최적의 초평면을 찾는 분류모델 알고리즘.
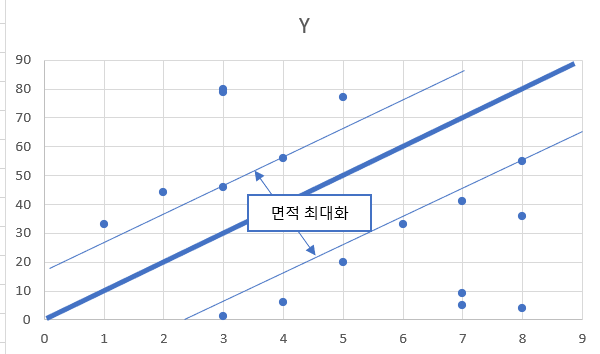
*KNN(K-Nearest Neighbor)
새로운 fingerprint 를 기존 클러스터 내의 데이터와 instance 기반거리를 측정하여 가장 많은속성을 가진 클러스터에 할당하는 분류알고리즘.

*의사결정나무(Decision Tree)
의사결정규칙을 도표화->관심대상이 되는 그룹을 소그룹으로 분류-> 예측을 수행하는 기법.
순환적 분할(Recursive Partitioning) 방식을 이용한 트리 구축.
가지분할 규칙: 엔트로피계수, 지니계수, 분류오류율 등
a. 주요 Parameter
-max_depth: 트리의 최대 깊이
-min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수
-min_samples_leaf: leaf(밑단노드)가 되기위한 최소한의 샘플 데이터 수
-max_features: 최적의 분할을 위해 고려할 최대 피처 개수
-max_leaf_nodes: leaf의 최대 개수
b. 시각화
Graphviz 패키지
*랜덤포레스트(Random Forest)
여러개의 의사결정트리의 다수결(voting) 을 통해서 모델의 성능 개선한 기계학습 방법.
XGBoost, LightGBM
*앙상블(Ensemble)
여러 분류모형에 대한 결과를 종합하여 한 데이터로 분류.
*로지스틱 회귀(Logistic Regression)
이항형 문제일 때(0or1, 참또는거짓) 사용. 독립변수의 선형 결합을 이용하여 개별관측치가 어느 집단에 속하는 지 확률을 계산.
*선형회귀(Linear Regression)
원인이 되는 값(x) 와 결과가 되는 값(y) 의 상관관계를 통계적 기법에 의해 조사. 하나,둘 이상의 독립변수들을 기초로 하여 종속변수에 미치는 영향력의 크기를 알아보는 기법.
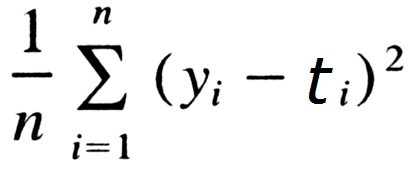
가설 설정 H(x)=Wx+b -> 비용함수 (가설,실제값 차이비교) -> 비용함수 최소값(미분=0) 찾는다
비용함수(MSE)
학습률 조절: 경사하강알고리즘(Gradient descent algorithm)을 통해 조절
'IT공부 > 인공지능-딥러닝,머신러닝' 카테고리의 다른 글
| 2. 딥러닝 이론 (0) | 2023.04.25 |
|---|---|
| 1. 딥러닝 역사 (1) | 2023.04.25 |
| 인공지능 딥러닝 머신러닝의 이해 (0) | 2023.04.25 |
| 머신러닝 학습방법 파이프라인 및 데이터 전처리 (1) | 2023.04.25 |
| 딥러닝 실습 (0) | 2020.11.01 |




댓글